

1. 개요

인터넷을 사용하다 보면 선착순 이벤트, 콘서트 예약, 합격자 조회 같은 특정 순간에 트래픽이 몰려서 사이트가 느려지거나 먹통이 되는 상황을 가끔 경험하게 됩니다.
이에 대한 해결책으로 캐싱, 쿼리 최적화, 대기열 시스템, 스케일 아웃, 스케일 업 등 다양한 해법이 알려져 있습니다. 이를 실제로 적용해보며 발생하는 문제와 이를 해결하는 방법을 모색하고자 합니다.
2. 성능 테스트 개요
이 프로젝트는 간단한 수강신청 시스템에 부하 테스트를 진행하고 성능 개선을 목표로 진행됩니다.
(https://github.com/kokoko12334/traffic_test)
| 애플리케이션 및 런타임 | Spring Boot:3.4.1, JDK:1.7 |
| 데이터 관리 | Redis:7.4.1, Mysql:9.1.0, Spring data JPA |
| 인프라 및 배포 | Nginx:1.25.1, Docker:24.0.2 |
| 테스트 도구 | nGrinder:3.5.8 |
2.1. 테이블 정보

- 사전 테스트 데이터
- 학생 5000명
- 교수 300명
- 과목 500개
2.2. 테스트 대상 API
| HTTP Method | API Endpoint | 설명 |
| GET | /api/students/{id} | 학생 정보를 단순 조회하는 기능. {id}는 학생의 고유 ID를 나타냄. |
| POST | /api/enrollments | 수강신청을 테이블에 업데이트하는 기능. student_id와 course_id로 학생과 과목을 묶어 수강신청을 기록. |
2.3. 테스트 환경 및 도구
- Docker 인프라 구성
- Docker 컨테이너를 이용하여 인프라를 구축하고 CPU, 메모리 자원을 제한하여 테스트를 실행합니다.
- 네트워크 지연은 반영하지 않습니다. 따라서 결과에 대해 좀 더 보수적으로 판단해야 합니다.
- DB (Database): 4GB 메모리, CPU 1코어
- Spring Boot 서버: 4GB 메모리, CPU 1코어
- 그 외 기타 컨테이너도 위와 동일한 스펙을 가집니다.
- 테스트 도구: nGrinder
nGrinder는 쉬운 UI 제공과 다양한 테스트 환경 설정이 가능합니다. 여러 사용자가 동시에 접속하는 상황에서의 부하 테스트를 쉽게 설정하고 실행할 수 있습니다.
3. Get 요청 성능 테스트

학생조회 테스트
- 테스트 시나리오: 사용자가 점차 증가하다가 초당 2000개의 요청을 3분 동안 테스트합니다.
- 목표: 초당 처리량(TPS) 2000, 평균 응답시간(MTT) 1000ms 이내
3.1. 단일 서버

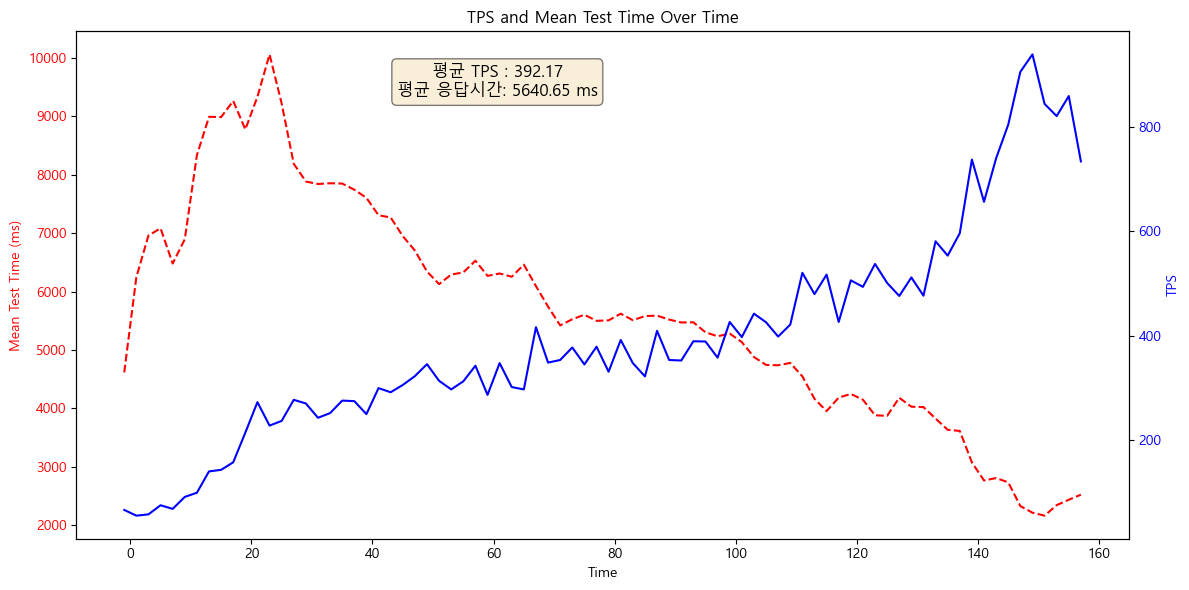
단일서버의 경우 평균 응답시간(MTT)이 5.6초, 평균 초당 처리량(TPS)이 390입니다. 목표했던 수치보다 현저히 떨어집니다. 또한, 피크타임(20초 쯤)에 응답시간이 10초로, 갑작스런 트래픽을 감당하지 못합니다.
3.2. 캐시 전략


조회된 항목을 메모리에 캐시합니다. 키-값 쌍으로 데이터를 저장하고 빠른 읽기/쓰기를 제공하는 인메모리 데이터베이스 인 Redis를 이용합니다.
평균 응답시간(MTT)이 4.4초, 평균 초당 처리량(TPS)이 508입니다.이전보다 개선되었지만 아직 부족한 수치이며 피크타임에는 여전히 느린 응답시간이 나옵니다.
3.3. 스케일 아웃


3개의 서버와 로드밸런서(Nginx)를 추가하여 트래픽을 분산 시킵니다.(http주소 라운드로빈 방식)
평균 응답시간(MTT)이 2.2초, 평균 초당 처리량(TPS)이 1700입니다. 많이 개선되었지만 피크타임의 응답시간은 8초로, 여전히 갑작스런 트래픽을 감당하지 못합니다.
3.4. Warm-up
Spring Boot 애플리케이션은 초기 시작 후 첫 번째 응답 시간이 느린 경우가 있으며, 이후부터 점차 성능이 개선되는 경향이 있습니다. 이러한 현상의 주요 원인은 다음과 같은 두 가지로 요약할 수 있습니다.
- JVM 클래스 로딩 (Class Loading)
JVM은 애플리케이션 실행 시 모든 클래스를 한 번에 메모리에 로딩하지 않고, 필요할 때마다 동적으로 클래스를 메모리에 올리는 지연 로딩(lazy loading) 방식을 사용합니다. 따라서 애플리케이션 초기 실행 시 필요한 클래스들이 로딩되며 시간이 소요되지만, 이후 호출 시에는 이미 메모리에 로드된 클래스들을 재사용하기 때문에 성능이 점차 개선됩니다.(https://docs.oracle.com/javase/specs/jls/se17/html/jls-12.html#jls-12.2) - JIT 컴파일러 (Just-In-Time Compiler)
JVM은 바이트코드를 실행할 때 초기에는 인터프리터 방식으로 코드가 실시간 번역되면서 실행되므로 상대적으로 느립니다. 하지만 JVM 내부의 JIT 컴파일러는 자주 호출되는 메서드와 코드 영역(핫스팟, Hotspot)을 감지하고, 이를 네이티브 코드로 컴파일하여 캐싱합니다. 이로 인해 실행 속도가 점진적으로 빨라지며, 최적화된 성능을 발휘합니다.
결론은 애플리케이션 시작 후 사전에 웜업(warm-up) 과정을 수행하는 것이 필요합니다. 자주 호출되는 API나 메서드를 강제로 호출하여 클래스 로딩, JIT 컴파일 최적화를 미리 완료하면, 실제 서비스 시 초기 응답 시간을 단축할 수 있습니다. 단, 초기에 cpu사용률이 높아질 수 있습니다.
@Component
public class AppWarmUp implements ApplicationListener<ApplicationReadyEvent> {
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
warmup1(); // 워밍업할 로직을 추가
warmup2();
warmup3();
}
}스프링부트에서 ApplicationListener를 구현하면 애플리케이션 시작 시 특정 이벤트를 감지하여 워밍업 작업을 수행할 수 있습니다.
아래는 자주 사용될 코드를 미리 호출하여 1분동안 warm-up 단계를 거친 이후의 결과입니다.

평균 응답시간(MTT)이 1초, 평균 초당 처리량(TPS)이 2600입니다. 피크시간대의 응답시간은 3초 이내입니다.
이를 통해 warm-up은 예상되는 트래픽 증가에 대한 대응 수단으로서 활용 될 수 있습니다.
- InnoDB를 이용한 DB Warm-up
DB에서도 Warm-up을 활용하여 성능을 최적화할 수 있습니다. 여기서는 성능 차이가 미미했기 때문에 간단히 언급만 합니다.
MySQL의 InnoDB는 버퍼 풀(Buffer Pool)이라는 캐시 메커니즘을 통해 디스크 I/O를 최소화하고 데이터 조회 속도를 향상시킵니다. 이 버퍼 풀을 활용하려면 SELECT 쿼리를 통해 자주 사용되는 데이터를 미리 메모리에 적재할 수 있습니다.

또한, InnoDB는 Dump와 Load 기능을 제공하여 버퍼 풀에 있는 데이터를 저장하고, 나중에 이를 다시 불러올 수 있습니다. 이를 위해 my.cnf 파일에 다음과 같은 설정을 추가할 수 있습니다:
- innodb_buffer_pool_dump_at_shutdown = ON: DB 종료 시 버퍼 풀에 있는 데이터를 자동으로 하드디스크에 저장
- innodb_buffer_pool_load_at_startup = ON: DB 시작 시 자동으로 덤프한 데이터를 버퍼 풀에 로드
명령어를 통해 직접 수행할 수도 있습니다:
- SET GLOBAL innodb_buffer_pool_load_now = ON;: 즉시 버퍼 풀 데이터를 로드
- SET GLOBAL innodb_buffer_pool_dump_now = ON;: 즉시 버퍼 풀 데이터를 덤프
- SET GLOBAL innodb_buffer_pool_dump_pct = 25;: MRU(Most Recently Used)기준상위 25%의 데이터만 저장
이 dump파일은 실제 데이터가 아닌 데이터의 위치를 가리키는 메타데이터(디스크 페이지 번호)입니다. 따라서 실제 데이터를 메모리에 로드하는 것이 아니라 디스크 I/O를 더 효율적으로 처리할 수 있는 기능입니다. 만약 실제 데이터를 초기화하려면 SELECT 쿼리를 통해 데이터를 미리 로드하여 메모리에 올리는 방법을 사용해야 합니다.
(참고: https://dev.mysql.com/doc/refman/8.4/en/innodb-preload-buffer-pool.html)
4. Post 요청 성능 테스트

수강신청 테스트
- 테스트 시나리오: 사용자가 점차 증가하다가 초당 1000개의 요청을 2분 동안 테스트합니다.
- 목표: 요청 초당 처리량(TPS) 1000, 응답시간 1000ms 이내.
4.1. 동시성 제어
수강신청은 다음의 절차를 따릅니다.
- 해당 과목의 "최대정원"과 "현재 수강인원"을 조회한다.
- (최대정원 > 현재 수강인원) 이라면 수강신청을 할 수 있다.
- 수강신청을 하면 현재 수강인원을 +1 증가시킨다.
이때 현재 수강인원을 여러 명의 사용자가 동시에 업데이트 요청을 한다면 경쟁 상태(race condition)가 되어 데이터가 이상해질 수 있습니다. 예를 들어, 수강신청 시스템에서 최대 정원이 50명인 과목에 여러 명의 사용자가 동시에 신청을 시도하면, 나중에 현재 수강인원이 50명을 초과할 수 있습니다. .
따라서 결론은, 동시에 수정요청이 들어오면 이를 제어하기 위한 Locking이 필요합니다.
이때 Read작업에도 MySQL의 Exclusive Lock를 사용하는 것이 필요합니다. 이는 Deadlock을 방지하기 위해서입니다.


MySql에서는 어떤 행(row)에 S-Lock(Shared-Lock)이 걸린 상태에서 X-Lock(Exclusive-Lock) 획득이 불가능해 서로 대기하는 데드락 상황이 발생합니다. 이를 방지하기 위해 읽기 쿼리에서도 SELECT FOR UPDATE를 사용해 명시적으로 Exclusive Lock을 걸어야 합니다.
(원래 MySQL의 기본 격리수준인 REPEATABLE READ에서는 MVCC를 사용하기 때문에 공유 잠금(S-lock)을 사용하지 않습니다. 그러나 외래 키 제약 조건이 있는 테이블에 대해서는 참조 무결성을 유지하기 위해 S-lock이 걸립니다.
SET GLOBAL FOREIGN_KEY_CHECKS = 0;으로 설정하면 S-lock을 안쓰기 때문에 데드락이 발생하지 않습니다.)
이로써, Lock으로 동시성 이슈와 Deadlock을 방지했지만, 이는 성능을 저하시킵니다. 따라서 Lock 없이 동시성을 처리할 수 있는 다른 방법이 필요합니다.
4.2. Redis를 이용한 동시성 제어
Redis에서 요청을 하나의 트랜잭션(원자적 연산)으로 묶어서 처리하면 별도의 락 없이도 동시성 제어를 할 수 있습니다. 다음은 Redis 선택의 이유를 정리한 것입니다.
- 메모리 기반: 임계구역(현재 수강인원)을 메모리로 옮겨 Disk I/O를 줄이고 연산 속도를 높입니다.
- 여러 자료구조 지원: Redis는 다양한 자료구조를 제공하므로, 필요에 따라 적합한 자료구조를 선택할 수 있습니다. 예를 들어, Set 자료구조는 중복 신청을 방지합니다.
- 원자적 연산 + 순차적인 처리: Redis는 Lua 스크립트를 사용하여 여러 절차를 원자적으로 정의하고 실행할 수 있으며, 기본적으로 싱글 스레드로 동작하여 요청을 순차적으로 처리합니다. 이를 통해 경쟁 상태(race condition)를 예방할 수 있습니다.
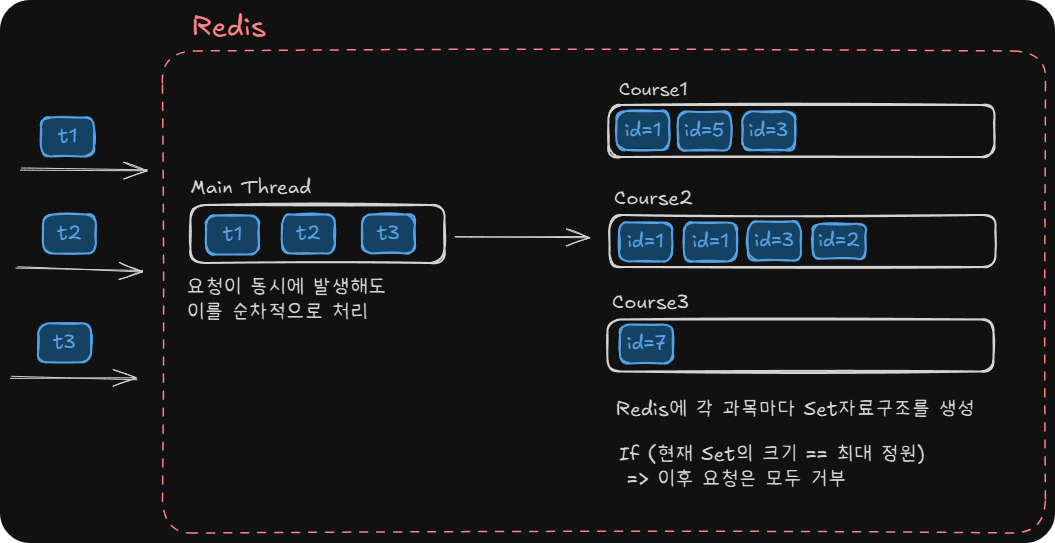
각 요청은 메인 스레드에서 처리되며, 별도의 동기화 메커니즘 없이도 데이터 정합성을 유지할 수 있습니다. Set 자료구조를 사용하여 중복을 방지하고, 최대 정원 초과 시 요청을 거부하여 (최대정원 >= 현재 수강인원)을 보장합니다.
주의할 점은, 데이터의 정합성을 유지하려면 로직을 애플리케이션 레벨이 아닌 Redis 내부에서 처리하도록 해야 한다는 것입니다.
Redis에서는 원자성을 보장하기 위해 Lua 스크립트를 사용하여 여러 명령을 하나의 트랜잭션으로 묶을 수 있습니다. Lua 스크립트는 Redis 서버 내에서 실행되어, 클라이언트와의 왕복을 줄이고 원자적 연산을 보장합니다.
** KEYS[1]=과목id, ARGV[1]=최대정원, ARGV[2]=학생id **
local currentSize = redis.call('SCARD', KEYS[1]) // 1.현재 수강인원을 조회한다.
local maxSize = tonumber(ARGV[1])
if redis.call('SISMEMBER', KEYS[1], ARGV[2]) == 1 then
return 0 // 2.같은 과목에 두 번 신청하는 경우는 없다.
end
if currentSize >= maxSize then
return 0 // 3.현재 수강인원이 정원을 넘어서면 신청할 수 없다.
end
redis.call('SADD', KEYS[1], ARGV[2])
return 1 // 4.위 두 개의 조건을 모두 통과하면 수강신청이 된다.
10만 개의 요청을 동시에 보낸 이후에 데이터의 정합성이 지켜졌는지 검증합니다.(모든 과목의 최대정원 50명)
RedissonClient redissonClient = Redisson.create(config);
int cnt = 0;
for (int i = 1; i < 501; i++) {
if (redissonClient.getSet(String.valueOf(i)).size() > 50) {
cnt++;
}
}
System.out.println("현재 수강인원이 최대 정원보다 높은 겨우: " + cnt + "개");
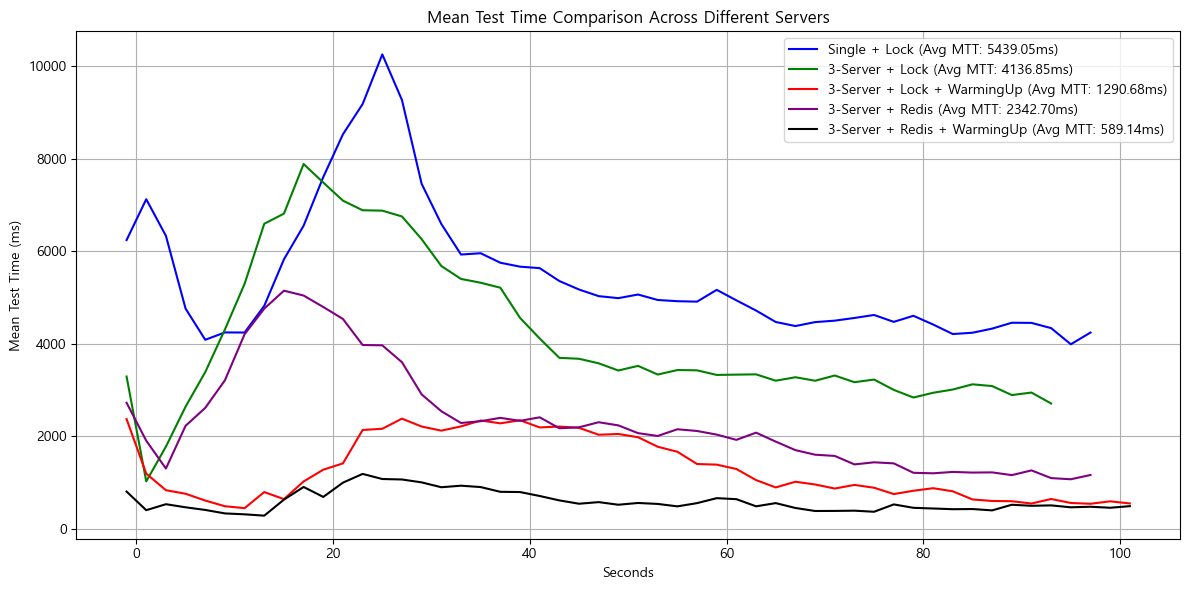
4.3. 시스템 구성별 성능 비교
- 단일 서버 + Lock
- scale out(3개) + Lock
- scale out(3개) + Lock + WarmingUp
- scale out(3개) + Redis
- scale out(3개) + Redis + WarmingUp
각 5가지의 경우를 비교합니다.
- 초당 처리량(TPS)

- 평균 응답시간(MTT)
5. 결론
- 시스템 구조: Scale-out(3개 인스턴스) + Redis + WarmUp 적용
- 테스트 시나리오: 5분 동안 초당 2000개의 트래픽 진행, POST(291,723개)+ GET(301,341개)동시 요청

GET, POST 요청을 랜덤으로 트래픽을 테스트한 결과, 평균 TPS는 2200, 평균 응답 시간은 0.7초로 나타났습니다. 전체적으로 대부분의 요청이 1초 이내에 응답하여 빠르고 안정적인 응답 시간을 유지하고 있음을 확인할 수 있습니다.
https://www.baeldung.com/spring-boot-startup-speed
https://www.baeldung.com/java-jvm-warmup
https://www.youtube.com/watch?v=CQi3SS2YspY
https://www.baeldung.com/jvm-tiered-compilation
https://blog.techeer.net/redis-3b94c9369d63?utm_source=chatgpt.com
'컴퓨터 > 프로젝트' 카테고리의 다른 글
| (프로젝트) SAM, Github action으로 서버리스 아키텍처 CI/CD구현 (0) | 2024.09.11 |
|---|---|
| (프로젝트) 만개의 레시피 데이터 수집 자동화 (0) | 2024.08.31 |
| (프로젝트) AWS를 활용한 간단한 최신 정보 알림 만들기 (0) | 2024.08.14 |
| 인턴생활 - 뉴스 데이터수집하기 (0) | 2024.03.30 |
| 인턴생활 정리 - 이것 저것 (0) | 2024.03.21 |