

1. 프로젝트 개요
1) 목적 및 배경
전자공시시스템(DART)에는 매일 수백 개의 공시가 올라오며, 이를 일일이 확인하는 것은 번거롭고 시간이 많이 소모됩니다. 중요한 공시를 신속하게 확인하는 것은 투자자에게 중요합니다. 따라서 내가 지정한 기업의 최신 공시를 이메일로 받아본다면 시간 절약에 큰 도움이 될 것입니다.
2) 주요 기능 요약
이 프로젝트는 1시간 마다 최신 공시를 조회하고 나의 관심기업에 대한 공시 내용을 이메일로 알림을 보내는 시스템을 구축하는 것을 목표로 합니다. 주요 기능은 다음과 같습니다
- 배치 작업: 1시간마다 DART API에 요청을 보내 오늘의 새로운 공시를 조회.
- 관심 기업 필터링: 사용자가 지정한 관심 기업의 최신 공시 정보를 필터링하여 제공.
- 이메일 알림: 필터링된 공시 정보를 사용자에게 이메일로 알림.
- 중복 처리: 이미 제공한 공시에 대해서는 중복 알림을 방지.
3) 기술 스택
- 서버 측 기술
1. AWS Lambda: Dart API 요청 및 이메일 알림 전송과 같은 서버 측 로직을 처리합니다.
2. AWS Step Functions: 워크플로우를 조정하고 관리하여 복잡한 작업을 자동화합니다.
3. AWS EventBridge: 주기적으로 Step Functions 워크플로우를 트리거하여 정기적인 작업을 수행합니다.
4. AWS SES (Simple Email Service): 이메일 알림을 사용자에게 전송하는 데 사용됩니다.
- 데이터베이스 및 스토리지
1. AWS S3 (Simple Storage Service): 공시 데이터 및 로그 문서를 저장하고 관리합니다.
- 언어 및 기타 라이브러리
1. Python: Lambda 함수 내 비즈니스 로직을 구현하는 데 사용되는 프로그래밍 언어입니다.
2. OpenDartReader: Dart API 요청을 클래스로 다루어 쉽게 API 요청을 관리할 수 있는 라이브러리입니다.
3. Pandas: 공시 정보를 데이터 프레임으로 쉽게 조작할 수 있도록 도와주는 데이터 분석 라이브러리입니다.
2. 아키텍처 개요
1) 시스템 아키텍처

모든 기술은 서버리스 아키텍처로 구현되며, 주요 흐름은 다음과 같습니다:
- 데이터/로직 흐름
1. EventBridge Scheduler 트리거
- 설정된 주기(1시간)에 따라 EventBridge Scheduler가 AWS Step Functions 워크플로우를 트리거합니다.
2. 최신 공시 정보 수집
- Step Functions의 첫 번째 상태에서 Dart-latest-lambda 함수가 실행되어 DART API에 요청을 보내 최신 공시 정보를 수집합니다.
- 수집된 공시 정보는 로깅을 위해 AWS S3에 저장됩니다.
3. 관심 기업 필터링
- 다음 단계에서, 수집된 공시 정보 중 사용자가 관심 있는 기업의 최신 공시가 있는지 확인합니다.
- 만약 관심 기업에 해당하는 공시가 없으면 워크플로우는 종료됩니다.
4. 이메일 내용 생성
- 관심 기업의 최신 공시가 존재할 경우, SES-lambda 함수가 실행되어 공시 정보를 포함한 이메일을 생성합니다.
5. 이메일 전송
- 생성된 내용은 AWS SES를 통해 사용자의 이메일 주소로 전송됩니다.
- 이 과정 역시 로깅을 위해 AWS S3에 저장됩니다.
3. 구현 세부 사항
1) Dart-latest-lambda
Dart-latest-lambda는 AWS Lambda를 활용하여 최신 공시 정보를 수집하고 이를 전처리하여 결과를 생성합니다.
1. 현재 날짜 기준 최신 공시 받아오기
utc_now = datetime.now(pytz.utc)
korea_tz = pytz.timezone('Asia/Seoul')
korea_now = utc_now.astimezone(korea_tz)
formatted_now = korea_now.strftime("%Y%m%d")
# 현재날짜를 기준으로 올라온 모든 공시를 조회합니다.
df = dart.list(start=formatted_now, end=formatted_now, final=False)현재 날짜를 기준으로 최신 공시 정보를 조회하여 데이터프레임 형태로 가져옵니다. 이 과정은 UTC 시간을 한국 시간으로 변환한 후 수행됩니다.
2. 오늘 조회된 공시 중 이미 처리한 내용을 S3에서 확인하여 중복 처리를 방지.
check = set()
try:
# 파일 존재 여부 확인
s3.head_object(Bucket=bucket_name, Key=file_key)
# 파일이 존재하면 불러오기
response = s3.get_object(Bucket=bucket_name, Key=file_key)
check = pickle.loads(response['Body'].read())
log_message(f"File exists. Content loaded: {check}")
except ClientError as e:
if e.response['Error']['Code'] == '404':
# 파일이 존재하지 않으면 새로 생성
serialized_data = pickle.dumps(check)
s3.put_object(Bucket=bucket_name, Key=file_key, Body=serialized_data)
log_message(f"File '{file_key}' not found. New file created.")
else:
log_message(f"Unexpected error: {e}")
except NoCredentialsError:
log_message("Credentials not available.")이 코드는 오늘 조회된 공시 중 이미 처리한 내용을 저장하여 중복 처리를 방지하는 기능을 수행합니다. S3 버킷에서 특정 파일의 존재 여부를 확인하고, 파일이 존재하면 해당 내용을 불러와 `check` 변수에 업데이트합니다. 만약 파일이 존재하지 않으면 새로 생성하여 `check`에 초기값을 저장하고, 이를 통해 1시간 전에 처리한 공시와의 중복을 방지합니다.
3. 공시 내용 필터링
# 나의 관심 기업(종목코드)
my_corp_list = {'900260', '004370', '005930', '290720', '222810', '176750', '005935'}
# 1. 필터링1: 관심 기업회사의 보고서만 필터링
df = dart.list(start=formatted_now, end=formatted_now, final=False)
my_corp_df = df[df['stock_code'].isin(my_corp_list)]
# 2. 필터링2: 중복된 보고서 제외
filtered_my_corp_df = my_corp_df[~my_corp_df['rcept_no'].isin(check)]
for i in range(len(filtered_my_corp_df)):
rcept_no = filtered_my_corp_df.iloc[i]['rcept_no']
check.add(rcept_no)
recent_reports = []
for i in range(len(filtered_my_corp_df)):
data = {
"corp_name": filtered_my_corp_df.iloc[i]["corp_name"],
"stock_code": filtered_my_corp_df.iloc[i]["stock_code"],
"report_nm": filtered_my_corp_df.iloc[i]["report_nm"].replace(" ", ""),
"rcept_no": filtered_my_corp_df.iloc[i]["rcept_no"],
}
recent_reports.append(data)두 단계의 필터링을 통해 관심 있는 기업의 보고서를 추출합니다.
"필터링1"에서는 `my_corp_list`에 포함된 기업의 보고서만 선택하여 `my_corp_df` 데이터프레임을 생성합니다. "필터링2"에서는 `check`에 이미 처리된 보고서의 접수 번호(`rcept_no`)가 포함된 경우를 제외하여 중복된 보고서를 필터링한 후, 최종적으로 `filtered_my_corp_df`를 생성합니다. 이후, 필터링된 보고서의 정보를 `recent_reports` 리스트에 저장하여 필요한 데이터 구조를 만듭니다.
4. 결과 반환
#결과
output = {
"state": state,
"recent_reports": recent_reports
}`recent_reports`에는 최종 보고서 공시 내용을 리스트 형태로 담고, `state`는 최신 보고서의 존재 여부를 판단합니다. 최신 보고서가 있는 경우 `state`는 `True`로 설정되고, 없으면 `False`로 설정하여 이후 워크플로우에 필요한 데이터를 전달합니다.
2) SES-lambda
client = boto3.client("ses", region_name="ap-northeast-2")
df = pd.DataFrame(recent_reports)
df_html = df.to_html(index=False, justify='center')
to_email = "email@email.com"
subject = "관심 기업의 최신 공시정보입니다."
body_text = ""
body_html = df_html
try:
response = client.send_email(
Destination={
"ToAddresses": [
to_email,
],
},
Message={
"Body": {
"Html": {
"Charset": "UTF-8",
"Data": body_html,
},
"Text": {
"Charset": "UTF-8",
"Data": body_text,
},
},
"Subject": {
"Charset": "UTF-8",
"Data": subject,
},
},
Source=sender,
)
log_message(f"Email sent! Message ID:{response["MessageId"]}")
except ClientError as e:
log_message(f"error:{e.response["Error"]["Message"]}")최신 공시가 존재하는 경우, 해당 데이터를 데이터프레임 형식으로 정리하여 HTML 표로 변환합니다. 이후에 지정한 이메일로 SES를 통해 전송합니다.
최종적으로 다음의 내용이 이메일로 전송됩니다.

3) 로그데이터
2024-08-23T15:00:08.036716+09:00 - Output: {'state': True, 'recent_reports': [{'corp_name': '푸드나무', 'stock_code': '290720', 'report_nm': '주식등의대량보유상황보고서(일반)', 'rcept_no': '20240823000222'}]}
2024-08-23T15:00:17.686517+09:00 - Email sent! Message ID:010c01917dd24ab3-05708ee4-2e20-4b15-88b7-aa9871f012b4-000000
2024-08-23T16:00:08.445494+09:00 - File exists. Content loaded: {'20240823000222'}
2024-08-23T16:00:08.445494+09:00 - Output: {'state': False, 'recent_reports': []}
2024-08-23T17:00:07.696972+09:00 - File exists. Content loaded: {'20240823000222'}
2024-08-23T17:00:07.696972+09:00 - Output: {'state': False, 'recent_reports': []}로그 데이터는 각 워크플로우의 결과값을 기록하여 데이터 흐름을 추적하도록 설정합니다. 예를 들어, 최신 공시가 존재할 경우 해당 정보를 포함한 출력이 생성되고 이메일이 전송된 후, 이후 작업에서 파일의 존재 여부와 그에 따른 결과가 기록됩니다.
4) StepFunction 상태머신 그래프
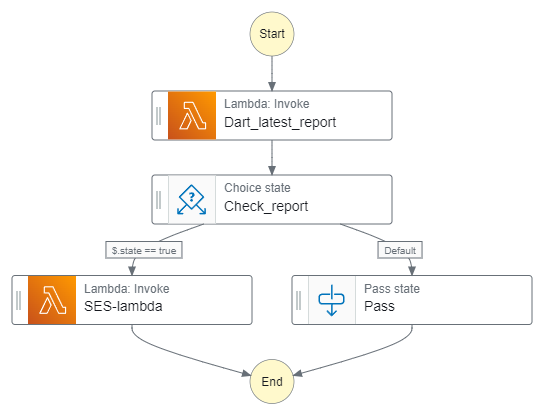
4. 기타 트러블 슈팅
1) 데이터 검증 누락
- 문제 발생


주말에 다음과 같이 Dart_latest_report에서 에러가 발생하여 전체 동작이 실패하였습니다.
- 원인 분석

"stock_code"키가 없다는 에러메시지를 확인할 수 있습니다.
df = dart.list(start=formatted_now, end=formatted_now, final=False)오늘의 공시 조회 시 아무런 공시가 없으면 데이터프레임(`df`)이 빈 값으로 반환되며, 이 경우 적절한 예외 처리가 이루어지지 않아 문제가 발생했습니다. 특히 주말에는 올라오는 공시가 없기 때문에, 이러한 상황에 대한 적절한 처리를 못한 것이 원인이었습니다.
- 해결 방안
문제를 해결하기 위해 두 가지 수정 사항이 있습니다.
1. 이벤트 스케줄러에서 주말 제외: 주말에 공시 조회를 수행하지 않도록 스케줄러를 설정하여 불필요한 조회를 방지합니다. 그러나 공휴일의 경우는 예측하기 어려워, 이를 일일이 지정하는 것은 비효율적입니다. 따라서 주말을 제외하는 것과 더불어 빈 데이터프레임에 대한 추가 조치를 해주어야 합니다.
2. 빈 데이터프레임 처리 로직 추가: 공시 조회 결과로 데이터프레임(`df`)이 빈 값일 경우에 대한 예외 처리를 추가하여, 시스템이 정상적으로 작동하도록 합니다. 이를 통해 공시가 없을 때 발생할 수 있는 오류를 예방합니다.
df = dart.list(start=formatted_now, end=formatted_now, final=False)
if df.empty:
return {
"state": False,
"recent_reports": []
}
- 검증

위 두 가지 사항을 적용하고 테스트 결과,
데이터프레임이 빈 값일 때도 시스템이 정상적으로 작동하는 것을 확인했습니다.
'컴퓨터 > 프로젝트' 카테고리의 다른 글
| 단기간 모의 테스트 (0) | 2024.12.29 |
|---|---|
| (프로젝트) SAM, Github action으로 서버리스 아키텍처 CI/CD구현 (0) | 2024.09.11 |
| (프로젝트) 만개의 레시피 데이터 수집 자동화 (0) | 2024.08.31 |
| 인턴생활 - 뉴스 데이터수집하기 (0) | 2024.03.30 |
| 인턴생활 정리 - 이것 저것 (0) | 2024.03.21 |